
The curl command is a powerful and versatile tool used to transfer data to or from a server using various protocols, such as HTTP, HTTPS, FTP, and more. It stands for “Client URL” and is commonly utilized for web requests, enabling users to download files, send data via POST requests, and even interact with RESTful APIs directly from the command line. The curl command can handle a wide range of tasks, from simple file downloads to complex multipart forms, and is often used in scripts for automation due to its flexibility and ability to provide detailed output, making it an essential utility in a Linux environment.
In this tutorial, we will discuss the curl command that, among other things, lets you download stuff from the Web. Please note that examples discussed in this article are tested on Ubuntu 24.04.
Linux curl command
The curl command allows you to download and upload data through the Linux command line. Following is its syntax:
curl [options] [URL...]
And here’s what the man page says about this command:
curl is a tool to transfer data from or to a server, using one of the
supported protocols (DICT, FILE, FTP, FTPS, GOPHER, HTTP, HTTPS, IMAP,
IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMTP, SMTPS,
TELNET and TFTP). The command is designed to work without user inter?
action.curl offers a busload of useful tricks like proxy support, user authen?
tication, FTP upload, HTTP post, SSL connections, cookies, file trans?
fer resume, Metalink, and more. As you will see below, the number of
features will make your head spin!curl is powered by libcurl for all transfer-related features. See
libcurl(3) for details.
Following are some Q&A-styled examples that should give you a better idea on how curl works.
Q1. How curl command works?
Basic usage is fairly simple – just pass the URL as input to the curl command and redirect the output to a file.
For example:
curl > test.torrent
Note that you can also use the -o option here.
-o, --output <file>
Write output to <file> instead of stdout.
Coming back to our example, while the data got downloaded in the ‘test.torrent’ file on my system, the following output was produced on the command line:
![]()
Here’s what the man page says about this progress meter that gets displayed in the output:
curl normally displays a progress meter during operations, indicating
the amount of transferred data, transfer speeds and estimated time
left, etc.curl displays this data to the terminal by default, so if you invoke
curl to do an operation and it is about to write data to the terminal,
it disables the progress meter as otherwise it would mess up the output
mixing progress meter and response data.If you want a progress meter for HTTP POST or PUT requests, you need to
redirect the response output to a file, using shell redirect (>), -o
[file] or similar.It is not the same case for FTP upload as that operation does not spit
out any response data to the terminal.If you prefer a progress "bar" instead of the regular meter, -# is your
friend.
Q2. How to make curl use same download file name?
In the previous example, you see, we had to explicitly specify the downloaded file name. However, you can force curl to use the name of the file being downloaded as the local file name. This can be done using the -O command line option.
curl -O
So in this case, a file named ‘ubuntu-18.04-desktop-amd64.iso.torrent’ was produced in the output on my system.
Q3. How to download multiple files using curl?
This isn’t complicated as well – just pass the URLs in the following way:
curl -O [URL1] -O [URL2] -O [URL3] ...
For example:
curl -O -O http://releases.ubuntu.com/18.04/ubuntu-18.04-live-server-amd64.iso.torrent
Here’s the above command in action:

So you can see the download progress for both URLs was shown in the output.
Q4. How to resolve the ‘moved’ issue?
Sometimes, when you pass a URL to the curl command, you get errors like “Moved” or “Moved Permanently”. This usually happens when the input URL redirects to some other URL. For example, you open a website, say oneplus.com, and it redirects to a URL for your home country (like oneplus.in), so you get an error like the following:
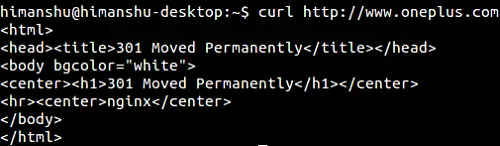
If you want curl to follow the redirect, use the -L command line option instead.
curl -L http://www.oneplus.com
Q5. How to resume a download from point of interruption?
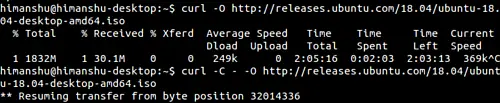
Sometimes, a download gets interrupted in between. So, to save time and data, when you try again, you may want it to begin from the point at which it got interrupted. Curl allows you to do this using the -C command line option.
For example:
curl -C - -O http://releases.ubuntu.com/18.04/ubuntu-18.04-desktop-amd64.iso
The following screenshot shows the curl command resuming the download after it was interrupted.
Conclusion
So you can see, the curl command is a useful utility if you like downloading stuff through the command line. We’ve just scratched the surface here, as the tool offers a lot more features. Once you are done practicing the command line options discussed in this tutorial, you can head to curl’s manual page to learn more about it.













{kind=link}